Welcome to vAccel Docs
This website contains documentation for vAccel, a set of software tools that semantically expose hardware acceleration functionality to isolated workloads running on VM sandboxes.
vAccel enables workloads to enjoy hardware acceleration while running on environments that do not have direct (physical) access to acceleration devices.
The design goals of vAccel are:
- portability: vAccel applications can be deployed in machines with different hardware accelerators without re-writing or re-compilation.
- security: A vAccel application can be deployed, as is, in a VM to ensure isolation in multi-tenant environments. QEMU, AWS Firecracker and Cloud Hypervisor are currently supported
- compatibility: vAccel supports the OCI container format through integration with the Kata containers framework [downstream].
- low-overhead: vAccel uses a very efficient transport layer for offloading "accelerate-able" functions from insde the VM to the host, incurring minimum overhead.
- scalability: Integration with k8s allows the deployment of vAccel applications at scale.
vAccel design
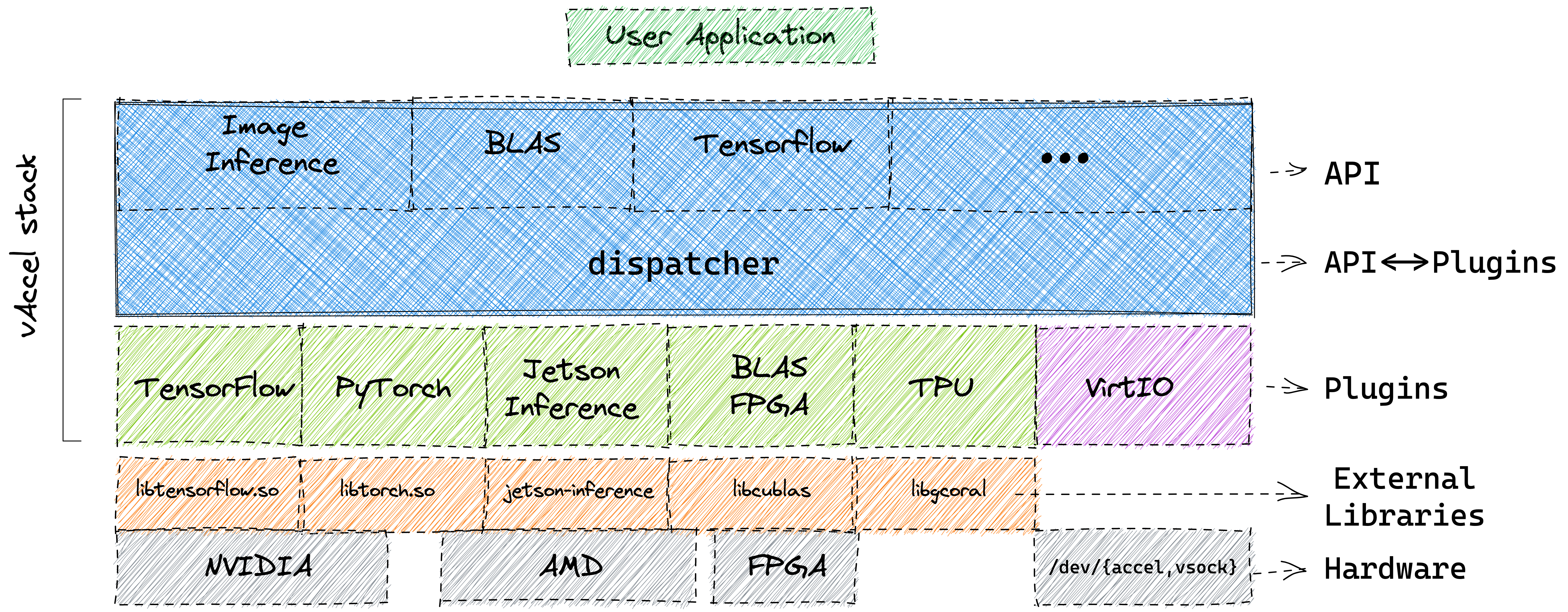
The core component of vAccel is the vaccel runtime library (vAccelRT). vAccelRT is designed in a modular way: the core runtime exposes the vAccel API to user applications and dispatches requests to one of many backend plugins, which implement the glue code between the vAccel API operations on a particular hardware accelerator.
The user application links against the core runtime library and the plugin modules are loaded at runtime. This workflow decouples the application from the hardware accelerator-specific parts of the stack, allowing for seamless migration of the same binary to different platforms with different accelerator capabilities, without the need to recompile user code.
The backend plugins conform to a simple plugin API. At the moment we have support for:
- Jetson inference framework, for acceleration of ML operation on Nvidia GPUs.
- Google Coral TPU, for acceleration on Coral TPUs.
- OpenVINO inference framework, for image inference on OpenCL-compatible accelerators (Intel CPU/GPUs, MyriadX chips etc.).
- Tensorflow inference, a simple inference program in TensorFlow.
- Tensorflow, with a limited number of operations and API calls supported.
- PyTorch, with a limited number of operations and API calls supported.
- Xilinx PYNQ, with a limited number of example programs supported.
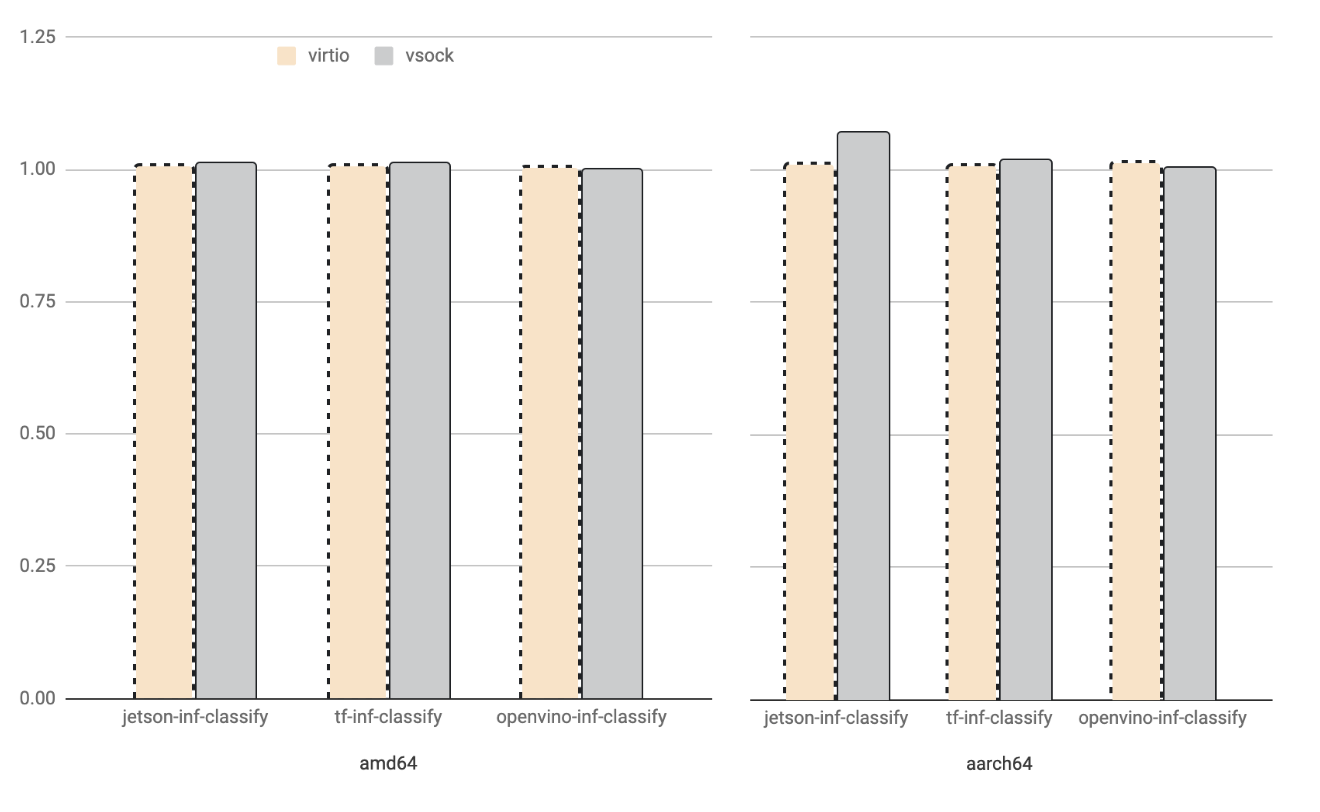
Hardware acceleration in Virtual Machines
Hardware acceleration for virtualized guests is, still, a real challenge. Typical solutions involve device pass-through or paravirtual drivers that expose hardware semantics inside the guest. vAccel differentiates itself from these approaches by exposing coarse-grain "accelerate-able" functions in the guest over a generic transport layer.
The semantics of the transport layer are hidden from the programmer. A vAccel application that runs on baremetal with an Nvidia GPU can run as is inside a VM using our appropriate VirtIO backend plugin.
We have implemented the necessary parts for our VirtIO driver in our forks of QEMU and Firecracker hypervisors.
Additionally, we have designed the above transport protocol over sockets,
allowing vAccel applications to use any backend, as long as there is a socket
interface installed between the two peers. Existing implementations include
VSOCK and TCP sockets. Any hypervisor supporting virtio-vsock can support
vAccel. See the relevant page for more
information.
Performance
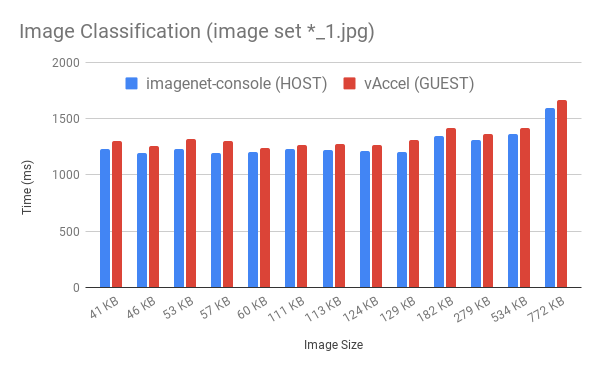
Figure 2 depicts a performance comparison of the image classification operation of a vAccel application running inside a Firecracker VM using the Jetson-inference plugin compared to the execution of the same operation using the Jetson-inference framework natively, running directly on the host.
The performance overhead of our stack is less that 5% of the native execution time across a range of image sizes.